When a system goes down unexpectedly, the questions come fast — how often does this fail, how long will it take to fix, and can we hit our uptime target? Those 3 numbers — MTBF, MTTR, and availability — are mathematically locked together, and getting any one of them wrong will break your maintenance planning. Use this Availability MTBF Calculator to calculate system availability, Mean Time Between Failures, Mean Time To Repair, and failure rates using operational data or target specs. It applies directly to manufacturing lines, data centers, mining fleets, and any other asset where downtime has a real cost. This page includes all 6 calculation modes, the full formula set, a worked example, and a practical FAQ.
What is Availability and MTBF?
Availability is the percentage of time a system is actually up and working. MTBF — Mean Time Between Failures — is the average number of hours between one failure and the next. Together, they tell you how reliable a piece of equipment really is.
Simple Explanation
Think of it like a delivery van. If it breaks down once every 500 hours of driving and takes 10 hours to fix each time, it's available roughly 98% of the time — that's availability. MTBF is just the average gap between breakdowns. The longer between failures and the faster the fix, the higher your availability.
📐 Browse all 1000+ Interactive Calculators
System Reliability Diagram

How to Use This Calculator
- Select your calculation mode from the dropdown — choose what you want to solve for (Availability, MTBF, MTTR, Failure Rate, or from raw operational data).
- Enter the required input values for your selected mode — MTBF in hours, MTTR in hours, availability as a percentage, or operating time and failure count depending on the mode.
- Use the "Try Example" button to load pre-filled values if you want to see a worked result first.
- Click Calculate to see your result.
Simple Example
Mode: Calculate Availability from MTBF & MTTR
- MTBF = 5000 hours
- MTTR = 24 hours
- Result: A = 5000 / (5000 + 24) = 99.52% availability
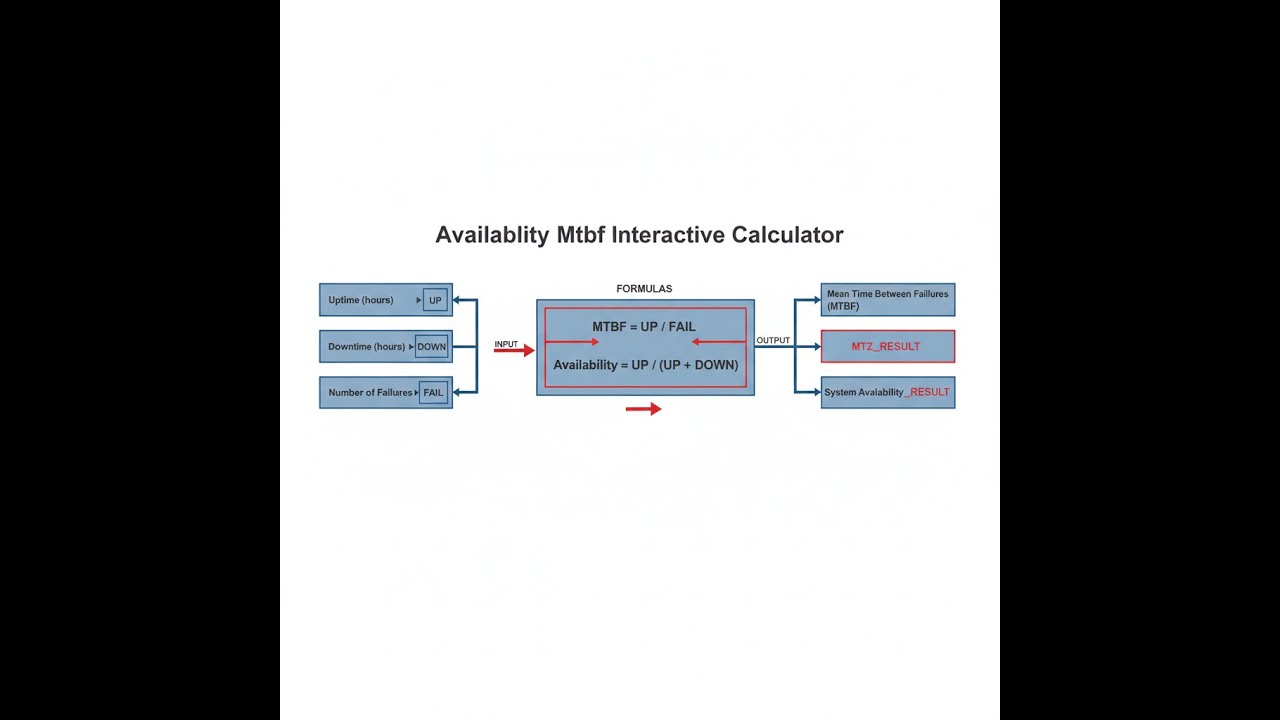
Availability & MTBF Calculator
Availability MTBF interactive visualizer
Visualize the mathematical relationship between Mean Time Between Failures, Mean Time To Repair, and system availability percentage. Adjust MTBF and MTTR values to see how repair speed and failure frequency directly impact overall system uptime.
AVAILABILITY
99.52%
FAILURE RATE
0.0002
UPTIME RATIO
208.3:1
ANNUAL DOWN
42 hrs
FIRGELLI Automations — Interactive Engineering Calculators
Reliability Equations
Use the formula below to calculate system availability.
System Availability
A = MTBF / (MTBF + MTTR)
A = Availability (decimal, multiply by 100 for percentage)
MTBF = Mean Time Between Failures (hours)
MTTR = Mean Time To Repair (hours)
Use the formula below to calculate MTBF from a known availability target and repair time.
MTBF from Availability
MTBF = (MTTR × A) / (1 - A)
Rearranged form solving for MTBF when availability target and repair time are known.
Use the formula below to calculate maximum allowable MTTR from a target availability and known MTBF.
MTTR from Availability
MTTR = MTBF × (1 - A) / A
Determines maximum allowable repair time to achieve target availability with known MTBF.
Use the formula below to calculate failure rate from MTBF.
Failure Rate
λ = 1 / MTBF
λ = Failure rate (failures per hour)
The instantaneous rate at which failures occur, assuming constant hazard rate (exponential distribution).
Use the formula below to calculate MTBF directly from field data.
MTBF from Operational Data
MTBF = Ttotal / Nfailures
Ttotal = Total operating time (hours)
Nfailures = Number of failures observed
Empirical calculation from field data or testing results.
Use the formula below to calculate availability from time-tracking records.
Availability from Uptime/Downtime
A = Tuptime / (Tuptime + Tdowntime)
Tuptime = Total time system was operational (hours)
Tdowntime = Total time system was non-operational (hours)
Direct calculation from time-tracking data over a measurement period.
Theory & Engineering Applications
System availability and Mean Time Between Failures represent fundamental metrics in reliability engineering, quantifying the fraction of time a system or component performs its intended function. These parameters drive critical business decisions including maintenance strategy selection, spare parts inventory optimization, warranty cost estimation, and capital equipment procurement.
Understanding the mathematical relationships between availability, MTBF, MTTR, and failure rates enables engineers to design systems that meet operational requirements while balancing reliability investment against total cost of ownership.
Fundamental Reliability Theory
Availability is defined as the probability that a system is operational at any given point in time, expressed as the ratio of uptime to total time. The relationship A = MTBF/(MTBF + MTTR) emerges from renewal theory, assuming failures follow a stationary stochastic process where the system alternates between operational and repair states. This formulation applies to repairable systems where components are restored to functionality after failure, distinguishing it from reliability R(t) = e-λt which describes non-repairable systems or time-to-first-failure scenarios.
The assumption of exponential failure distribution (constant hazard rate λ = 1/MTBF) simplifies analysis but has important limitations. Real-world systems often exhibit bathtub curves with decreasing hazard rates during burn-in, constant rates during useful life, and increasing rates during wear-out. The exponential model provides conservative estimates during the constant hazard phase but becomes inaccurate for aging equipment. Weibull distributions with shape parameter β ≠ 1 more accurately model wear-out (β greater than 1) and infant mortality (β less than 1), requiring modified MTBF calculations incorporating the gamma function: MTBF = η·Γ(1 + 1/β) where η is the Weibull scale parameter.
MTTR Components and Hidden Losses
Mean Time To Repair encompasses more than wrench time — it includes failure detection lag, diagnostic time, spare parts procurement and logistics, administrative delays, and system restart/testing. In practice, MTTR often exceeds active repair time by factors of 2–5×. A hydraulic pump mechanical seal replacement might require 3 hours of actual work, but if failure detection takes 45 minutes, diagnosis takes 1 hour, parts ordering requires overnight shipping, and post-repair testing takes 2 hours, the effective MTTR becomes 27 hours. This distinction between Mean Time To Repair (hands-on work) and Mean Time To Restore (total downtime) significantly impacts availability calculations.
Condition-based monitoring systems reduce MTTR by enabling predictive maintenance before failures occur, eliminating detection lag and reducing unplanned downtime. Vibration analysis on rotating equipment can identify bearing degradation weeks before failure, allowing planned replacement during scheduled maintenance windows rather than emergency repairs. This shifts maintenance from reactive (high MTTR) to proactive (lower effective MTTR through planned downtime), improving availability without necessarily changing MTBF.
Series and Parallel System Configurations
For systems with multiple components in series (where all must function), overall availability equals the product of individual availabilities: Asystem = A1 × A2 × ... × An. A production line with six stations each having 98% availability achieves only Asystem = 0.986 = 88.6% overall availability, demonstrating how serial dependencies rapidly degrade system performance. This multiplicative effect explains why complex systems with many components require extremely high individual component reliability to achieve acceptable system-level availability.
Parallel redundancy (where only one component needs to function) dramatically improves availability through the complement rule: Aparallel = 1 - (1 - A1)(1 - A2)...(1 - An). Two pumps in hot standby configuration, each with 95% availability, achieve system availability of 1 - (1 - 0.95)2 = 99.75%. However, common-mode failures (events affecting both redundant components simultaneously, such as contaminated fuel or electrical surges) reduce practical availability below theoretical calculations. A common-mode failure rate of 5% reduces the dual-pump availability from 99.75% to approximately 99.5%, illustrating the importance of failure independence assumptions.
Industry-Specific Availability Requirements
Different industries impose dramatically different availability targets based on economic consequences of downtime and safety criticality. Data center Tier IV facilities require 99.995% availability (26 minutes annual downtime), achieved through N+1 redundancy on all systems including cooling, power, and network infrastructure. Telecommunications carriers target "five nines" (99.999%) or 5.26 minutes annual downtime for critical switching equipment, driving mean time to repair below 15 minutes through extensive sparing and trained on-site personnel.
Manufacturing availability requirements depend on production value streams and buffering capacity. High-volume automotive assembly lines with minimal work-in-process buffers require 95–98% availability for critical bottleneck operations, translating to MTBF values of 400–800 hours with 4-hour MTTR targets. Conversely, batch chemical processes with days of in-process inventory can tolerate 85–90% availability on secondary equipment. Mining operations often design for 85–90% availability on mobile equipment, accounting for harsh operating conditions and remote locations that increase MTTR through longer parts delivery times.
Availability vs. Utilization Distinction
A critical but often misunderstood concept: availability measures technical uptime (ready to operate), while utilization measures productive output (actually operating). A machine can have 99% availability but 60% utilization if production scheduling, material shortages, or labor constraints leave it idle 40% of available time. Overall Equipment Effectiveness (OEE) combines availability with performance efficiency and quality rate: OEE = Availability × Performance × Quality. A stamping press with 95% availability, 85% speed efficiency (due to intentional slowdowns), and 98% first-pass yield achieves OEE = 0.95 × 0.85 × 0.98 = 79.1%, revealing significant improvement opportunities despite apparently high availability.
Worked Example: Production Line Availability Analysis
Consider a semiconductor wafer fabrication tool used for photolithography in a 24/7 fab. Over one quarter (2190 hours), the equipment experiences the following:
- Number of failures: 14 unplanned stops
- Total downtime: 127 hours (including all detection, diagnosis, repair, and restart time)
- Total uptime: 2063 hours
- Preventive maintenance: 3 scheduled events consuming 18 hours (counted as uptime for availability purposes)
Step 1: Calculate actual availability from uptime/downtime
A = Tuptime / (Tuptime + Tdowntime) = 2063 / (2063 + 127) = 2063 / 2190 = 0.9420 = 94.20%
Step 2: Calculate MTBF from operational data
MTBF = Ttotal / Nfailures = 2190 / 14 = 156.43 hours between failures
Step 3: Calculate MTTR from downtime and failure count
MTTR = Tdowntime / Nfailures = 127 / 14 = 9.07 hours per repair event
Step 4: Verify availability using MTBF/MTTR formula
A = MTBF / (MTBF + MTTR) = 156.43 / (156.43 + 9.07) = 156.43 / 165.50 = 0.9452 = 94.52%
The slight discrepancy (94.20% vs 94.52%) arises because the MTBF/MTTR formula assumes steady-state conditions while the direct calculation reflects the actual measurement period. The tool's current performance falls short of the fab's 96% availability target.
Step 5: Determine required MTTR to achieve 96% availability target
Rearranging A = MTBF / (MTBF + MTTR) to solve for MTTR:
MTTR = MTBF × (1 - A) / A = 156.43 × (1 - 0.96) / 0.96 = 156.43 × 0.04 / 0.96 = 6.52 hours
To reach 96% availability with current MTBF = 156.43 hours, MTTR must be reduced from 9.07 hours to 6.52 hours — a 28% reduction requiring approximately 2.5 hours per event improvement.
Step 6: Alternative approach — improve MTBF while holding MTTR constant
MTBF = (MTTR × A) / (1 - A) = (9.07 × 0.96) / (1 - 0.96) = 8.71 / 0.04 = 217.75 hours
Alternatively, maintaining MTTR = 9.07 hours requires increasing MTBF from 156.43 to 217.75 hours — a 39% improvement through better preventive maintenance, higher quality spare parts, or improved operating procedures.
Step 7: Calculate failure rate and interpret
λ = 1 / MTBF = 1 / 156.43 = 0.006392 failures per hour = 0.6392% per hour
This translates to approximately 56 failures per year (8760 hours), significantly higher than the "world-class" semiconductor fab target of 24–30 failures per tool per year, suggesting systematic reliability improvement initiatives are warranted.
This example illustrates the practical decision framework: reliability teams can improve availability by increasing MTBF (redesign, better parts, preventive maintenance), decreasing MTTR (spare parts stocking, technician training, diagnostic tools), or both. The economic optimization balances improvement costs against downtime costs, typically finding MTTR reduction more cost-effective initially (diminishing returns beyond certain thresholds), then pursuing MTBF improvements for further gains.
For additional reliability engineering resources and calculation tools, visit the FIRGELLI Engineering Calculator Library featuring specialized calculators for maintenance optimization, reliability prediction, and system availability analysis.
Practical Applications
Scenario: Manufacturing Line Reliability Planning
Jessica is a reliability engineer at an automotive components plant responsible for a new CNC machining cell producing transmission housings. The cell must achieve 95% availability to meet production volume commitments of 280,000 units annually. The equipment vendor quotes MTBF = 720 hours based on field data from similar installations. Jessica uses the availability calculator in MTTR-solving mode, entering 95% target availability and 720-hour MTBF. The calculator reveals she has a maximum allowable MTTR of 37.89 hours to hit her target. Breaking this down into components—failure detection (2 hours average), diagnosis (3 hours), parts procurement (24 hours for overnight shipping), repair (6 hours), and testing (2 hours)—totals 37 hours, leaving almost no margin. She negotiates with the vendor to stock critical spare parts on-site, eliminating the 24-hour shipping delay, and implements vibration sensors for faster failure detection, reducing her effective MTTR to 18 hours and achieving 97.6% availability with safety margin above the 95% requirement.
Scenario: Data Center SLA Compliance
Marcus manages IT infrastructure for a cloud service provider with contractual commitments to deliver 99.95% uptime on virtual machine hosting services. Over the past year (8760 hours), his servers experienced 47 minutes of unplanned downtime across 3 incidents. Using the calculator's uptime/downtime mode, he enters 8759.22 hours uptime and 0.78 hours downtime (47 minutes), calculating actual availability of 99.9911%—comfortably exceeding his SLA. However, he's concerned about one aging storage array showing early warning signs. The array has MTBF = 35,000 hours according to the manufacturer, but repairs require specialized vendor technicians with typical 8-hour response time for a total MTTR of 12 hours. He uses the availability-from-MTBF mode to predict this array would deliver only 99.9657% availability—below his SLA threshold. Marcus justifies implementing N+1 redundancy for the storage tier, calculating that two arrays in active-active configuration would achieve 1 - (1 - 0.999657)² = 99.999988% availability, virtually eliminating storage as a single point of failure.
Scenario: Mining Equipment Maintenance Optimization
David is the maintenance superintendent at an open-pit copper mine operating ten 400-ton haul trucks that represent the fleet bottleneck. Over the past six months (4380 operational hours per truck), his fleet logged 1,752 total operating hours of unplanned downtime across 146 failure events. Using the MTBF-from-failures calculator mode, he enters 43,800 total operating hours (10 trucks × 4380 hours) and 146 failures, yielding MTBF = 300 hours—far below the OEM's quoted 850 hours, suggesting either harsh operating conditions or maintenance gaps. He then enters the 1,752 hours downtime with 146 failures to calculate MTTR = 12 hours per event. Using the availability calculator, he computes current fleet availability of 300/(300+12) = 96.15%. However, production planning requires 97.5% availability to meet ore delivery targets. David uses the MTBF-solving mode: entering 97.5% target availability and 12-hour MTTR reveals he needs MTBF = 468 hours—a 56% improvement. He implements a condition monitoring program focusing on engine oil analysis, hydraulic system inspections, and tire pressure monitoring, reducing random failures. Six months later, recalculating with 89 failures over the same operating time yields MTBF = 492 hours and availability of 97.6%, meeting production requirements and demonstrating a quantifiable maintenance ROI of $3.2M annually in avoided production delays.
Frequently Asked Questions
What is the difference between MTBF and MTTF? +
Why does my calculated availability differ from field-measured availability? +
How do I improve availability: focus on MTBF or MTTR? +
Should scheduled preventive maintenance count toward availability? +
How does redundancy affect system availability calculations? +
What availability targets are realistic for different industries? +
Free Engineering Calculators
Explore our complete library of free engineering and physics calculators.
Browse All Calculators →🔗 Explore More Free Engineering Calculators
About the Author
Robbie Dickson — Chief Engineer & Founder, FIRGELLI Automations
Robbie Dickson brings over two decades of engineering expertise to FIRGELLI Automations. With a distinguished career at Rolls-Royce, BMW, and Ford, he has deep expertise in mechanical systems, actuator technology, and precision engineering.
Need to implement these calculations?
Explore the precision-engineered motion control solutions used by top engineers.



